System Overview
Video: RAZER in action - demonstrating real-time 3D scene understanding
capabilities with open-vocabulary semantic mapping.
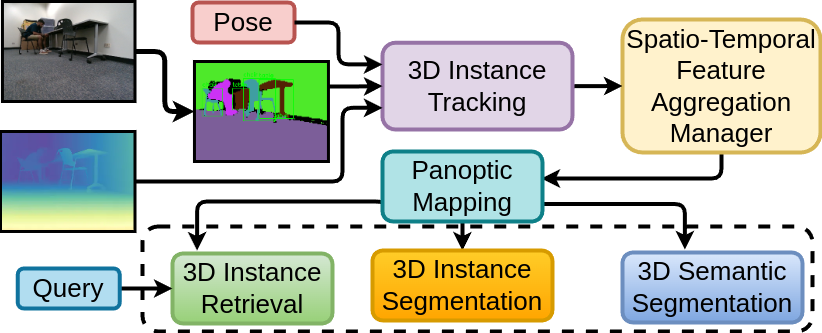
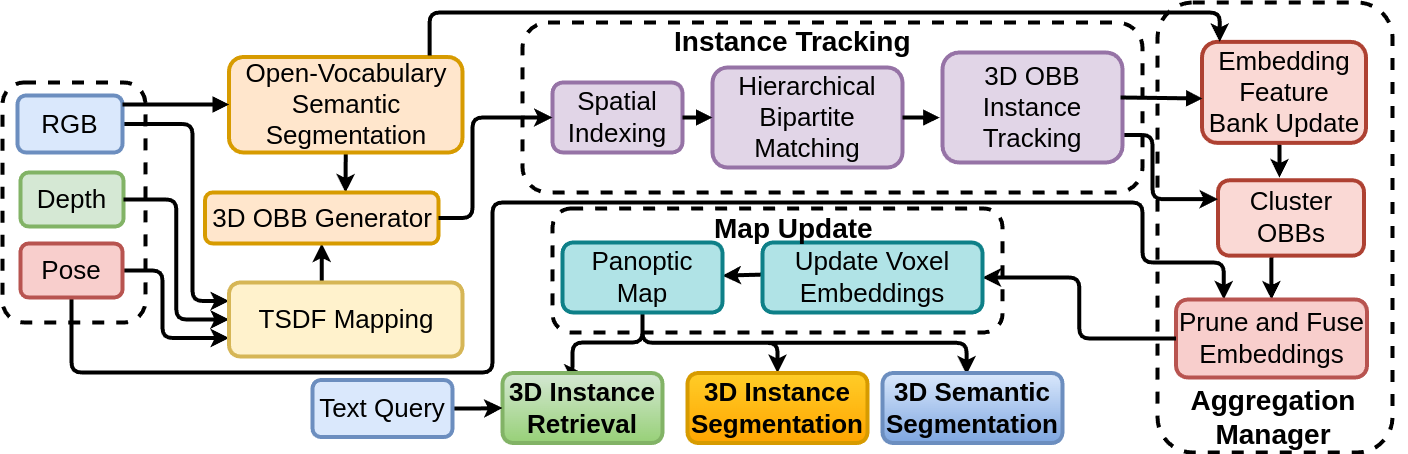
Figure 1: Pipeline overview of our proposed 3D scene understanding framework. Our
system processes posed RGB-D inputs through open-vocabulary segmentation for robust 3D instance
tracking. Spatio-temporal feature aggregation fuses and prunes tracks while updating a panoptic map
that enables online text-based 3D instance retrieval and segmentation tasks.